Yesterday we gave a talk about our summer at Donut.js! It was a lot of fun talking about Servo to a crowd of mostly(?) web developers. More info about this to come….
Today is the last day of RGSoC. We are incredibly sad, and proud of our summer!
Things we did:
Both of us worked on a secret blog post. It will be ready soon!
Things we learned:
A couple failing tests and their reasons:
assert_equals: response type is basic expected "basic" but got "default"
our API for returning responses (ie. process_response) doesn’t differentiate between the different types yet, so we need to make that possible to make those tests pass. Josh thinks that FetchMetadata will need to be changed.
assert_equals: Content-Type is text/html; charset=utf-8 expected "text/html;charset=utf-8" but got "text/html; charset=utf-8"
Spent the morning categorizing fetch/api/basic tests. >90% of failing tests were due to fetch is not defined. The remaining two failures were due to assert_equals: Request.text() should decode data as UTF-8 and assert_equals: Response.text() should decode data as UTF-8 expected. In the afternoon fetch got merged into master, so I retested response and basic at that point….now there is a lot of assert_equals: Request.text() should decode data as UTF-8 expected and assert_equals: Response's type is basic expected "basic" but got "default". Started trying to figure out what’s wrong with body’s text() Looked into request/request-consume.html and /basic/text-utf8.html….not sure how to fix!
Jeena
Started writing a blog post that is a secret yet!
TODO:
Test Curation
Possibly update because fetch and body are now merged.
Started fixing the Body implementation based on jdm’s feedback
Filed issue #13465 related to allowing trait object in promise.rs.
Filed issue #13464 about rethrowing exceptions instead of clearing pending JS exceptions in Body’s Json() method.
The error we were getting was due to having an error in the webidl! We should have used Promise<any> instead of Promise<JSON>.
Looked into form data crate for parsing Form Data. formdata::read_formdata requires a reader, and I’m not entirely sure how we can use this parser without stream or HttpReader.
General
We had lunch with Coach Stefan! We started thinking about what to do after this Friday when the summer of code is over…
We finished writing our end-of-summer blog post.
We went over the fetch method code to understand it better.
Trait object in Rust. Trait objects are the difference between fn foo(object: &Trait) (this is trait object) and fn foo<T: Trait>(object: &T). The former will result in the compiler generating less code, so the compile time will be faster. However, this puts a little more strain during run time, because it will have to check whether the parameter object implements the &Trait. The latter generates more code during compilation because it will create unique functions for each type that implements Trait. This saves time during run time because the functions for each type is already defined. As Josh said “classic tradeoff between time and space!”
Spent the morning (!!) rebasing Body on top of master (did it the hard way using rebase the first time, until Jeena suggested I just reset and cherry-pick my commits on top…the latter way had only a few merge conflicts as opposed to a LOT). And a little rewriting to get things to compile. Still need to implement the BodyTrait for request.rs. More tests are passing now!! Yay :)
Fetch
Hmm, homu tests kept failing. Web platform tests related to cors/ and redirect/ seemed to fail intermittently, so we decided to skip those tests for now.
Package Data Algorithm
The parser for body when MIMEType is “multipart/form-data” is not clearly defined, so I decided to skip it for now.
General
We started writing our end-of-summer blog post. So sad!
Things we learned:
git cherry-pick is sometimes easier than git rebase
git clean -f -d gets rid of untracked files and directories. I used this today right before a git reset.
TODO:
Body
The JSON function still does not work. getting error: WebIDL.WebIDLError: error: Unresolved type '<unresolved scope>::JSON'
Finished refactoring (for the most part) and pushed to a temporary branch for the Body API while Jeena adds her changes. I’ll probably implement the BodyTrait for dom::request while she does that.
Package Data Algorithm
Added/Refactored the package data algorithm to the temporary branch! And it compiles!
Things we learned:
You can directly access struct fields only if you’re in the same file as the struct that you’re trying to access. This at first seemed really weird and arbitrary to me, but apparently this turns out to be less of a headache (and fairly reasonable) compared to the way internal field access would be handles in C++ (according to our coach Nick). This is why it sometimes easier to implement a trait for a struct in the same file that the struct is defined (as opposed to, say, the file that the trait is defined).
TODO:
Body (Malisa)
implement the BodyTrait for dom::request. Also, rebase on top of the current master (now that promises and fetch are merged in ^^)
Test Curation
Go through the new tests, and categorize them.
Package Data Algorithm
Figure out how to write FormData() when MIMEType is “multipart/form-data”
Started refactoring consume_body based on feedback and yesterday’s planning. Created body.rs and pulled out consume_body and run_package_data_algorithm into it, and created a BodyTrait. The project was oddly compiling without complaints for most of the day. I mentioned this to Jeena, who reminded me that I have to list new dom files it in dom/mod.rs……haha. :) I did, and then all my bugs were then revealed upon the next compile. :P
Promise in Fetch
net_traits had changed! So I had to modify the process_response() method to accomodate the changes. It is more secure now as it allows the fetched data to be filtered. Filter exists to protect sites from having their data stolen by other sites.
Package Data Algorithm
I implemented(though no guarantee it works ) Json(), Blob(), and part of FormData().
Things we learned:
Moment of Realization
One of the reasons why I (Malisa) write code so slowly is that I feel like I need to understand every little thing about the codebase (at least, the parts I touch) prior to writing code. I’m unwilling to accept that Servo can just be MagicTM. But I think I’m starting to realize that going “down the rabbit hole” for each little detail can actually be somewhat counter-productive. Going to try to believe in magic a little more from now on.
If an enum has a type that is a struct/enum, the match statement will need to be comprehensive to cover the struct’s fields or enum’s types. For example, say there are two enums:
matchme{HavePet::No=>println!("I wish I had a pet!"),HavePet::Yes=>println!("I have a pet!"),}
The compiler will say that:
error: `HavePet::Yes` does not name a tuple variant or a tuple struct [--explain E0164]
--> <anon>:22:5
|>
22 |> HavePet::Yes => println!("I have a pet!"),
|> ^^^^^^^^^^^^
The correct way to write the match statement is:
matchme{HavePet::No=>println!("I wish I had a pet!"),HavePet::Yes{animal:Animal::Dog,how_many:_,}=>println!("I have dog(s)!"),HavePet::Yes{animal:Animal::Cat,how_many:_,}=>println!("I have cat(s)!"),}
matchme{HavePet::No=>println!("I wish I had a pet!"),HavePet::Yes{animal,..}=>matchanimal{Animal::Dog=>println!("I have dog(s)!"),Animal::Cat=>println!("I have cat(s)!"),}}
Link to play-rust is here. There is a github issue open for rust-lang to print out more helpful hints about this matter.
TODO:
Body
debug and finish refactoring. Push to github and then merge with Jeena’s implementation of Blob() and FormData(). Then work on Body for Request.
Test Curation
Go through the new tests, and categorize them.
Package Data Algorithm
Figure out how to write FormData() when MIMEType is “multipart/form-data”.
We decided that I should work on implementing the rest of the package data algorithm. This decides what to do given a Body, depending on its type (a text, json, and etc). Malisa already implemented text, so that’s great! Malisa will focus on going through review comments from her recent PR, and refactoring consume_body and making it into a public function. That way, it can be called by both Request and Response. At this moment, consume_body is customized for Response specifically, and it will be redundant to do the write the same function for Request.
Ms2ger implemented OpenEndedDictionary! This is what will allow more Headers/Request/Response tests to pass. Woohoo!
So I modified our Headers and Request APIs to adapt to this change. I fought with the borrow checker a lot today, but overall, it was successful. Thanks rustc!
Body
Got dom::Response’s Body text() function to the point that it compiles, but additional tests are not passing. I keep getting the same error Promise is not defined in testharness.js.
Things we learned:
When T doesn’t derive clone, or has a clone implementation, the compiler makes another reference when .clone() is called to a &T, ending up with &&T. When .clone() is called, the compiler derefs &T to T, realizes T cannot be cloned, and so it creates a clone to the reference, hence creating a double reference.
TODO:
Promise in Fetch
Go through failing tests and figure out what I can fix.
Test Curation
Go through the new tests, and categorize them.
OpenEndedDictionary in DOM
Is it time for a PR?
Body
Figure out whether I have a bug. Ask jdm. Then submit PR.
Today is our first day back from Strange Loop…more about that in the next couple days! P.S. It was really cool!
Things we did:
Promise in Fetch
Opened a PR. This surprisingly took a while because while we were at StrangeLoop, many things happened in the other corners of the Servo codebase!
I still have to go through the failing tests and figure out what can be fixed now.
Test Curation
Realized that the web platform tests have been updated! So there are more tests, and more tests are failing. This made the test curation work I did outdated, so this will have to be redone.
Body
Worked on editing my current code in order to get it to a compiling state. Figured out details like function return types, whether or not I need to implement certain spec steps, etc.
Things we learned:
[not Servo related] How interpreters work! Malisa and I wrote a simple interpreter in Rust yesterday! Thanks very much to our coach Nick.
TODO:
Promise in Fetch
Go through failing tests and figure out what I can fix.
Test Curation (Jeena; lower priority)
Go through the new tests, and categorize them.
Body
Get the code to a compiling state. Then figure out if I should get some tests passing and if I should implement more functions (not just text()) prior to a PR.
Day 50! Today was a good day. We listened to our mentor Josh give a great talk about Optimizing your project for contribution. As mentees, we really appreciate all the work that’s put into making Servo accessible to beginners.
Things we did:
Promise in Fetch
So yesterday, we found that JSCompartment::wrap had a parameter with a null pointer, which was the reason Servo was crashing. Josh recommended looking at dom/testbinding.rs to see how JSAutoCompartment is used, and to copy it in fetch.rs. After a little bit of wrestling with fetch.rs (because I mistakenly looked at the wrong code), fetch, at least for now, works!
Some more explanation on JSCompartments is at the Today We Learned section. What was happening yesterday with the null pointer was that promise didn’t enter any compartment, because JSAutoCompartment::new() wasn’t called. promise had not entered any compartment, and therefore, when SpiderMonkey (JS Engine) called JSCompartment::wrap(), which would take a JSContext to the compartment of a JSObject, a null pointer was given. Apparently in order to enter a compartment, JSContext has to already have entered a compartment. And that’s why Servo crashed!
We had been doing systems programming for two months, and this was our first time encountering a null pointer (which was in C++ code). Nick said that this shows how safe Rust is, because Rust would not have compiled in the first place. I haven’t programmed in C++, but it must be annoying if a code compiles and so much time could pass until you find a memory pointer bug.
I still didn’t get a lot of code-writing done, but I have a better idea of where I’m headed now. I was unsure how closely I should be following the spec for utf-8 decoding. I asked jdm, and it turns out the answer is “just closely enough” (my own words). So that’s good, and I think I’m starting to understand how to not get super caught up in spec-reading loops of infinite link-following. It also turns out I can make use of the encoding crate, which I believe means a lot of the actual decoding part has already been written for me.
Things we learned:
Spider Monkey specific: What is JSAutoCompartment? JSAutoCompartment helps a JSContext to enter a compartment, and leave the compartment when it is out of scope.
Spider Monkey specific: What is a Compartment? Every JSContext has a current Compartment, but it won’t enter its current compartment until JSAutoCompartment::new() is called. In a browser, one tab (one window) will have at least one compartment. Two tabs will have at least two compartments. Compartment is important for security, because there can be little cross-over that will be strictly controlled. You wouldn’t want data jumping back and forth between different compartments.
TODO:
Body
continue with UTF-8’s decoder. Now I really need to flesh out the code.
Fetch Tests
It’s time to go through the failing tests and see how to improve fetch.rs!
Ran 104 tests finished in 100.0 seconds.
- 53 ran as expected. 0 tests skipped.
- 2 tests crashed unexpectedly
- 4 tests timed out unexpectedly
- 48 tests had unexpected subtest results
On Friday, wrapping Rc<Promise> with Trusted didn’t work. Over the weekend Josh pushed another commit to enable Trusted<Promise> and TrustedPromise::root() that will return a Rc<Promise>. On Sunday, I encountered two borrow check errors:
process_response requires &mut self as a parameter (not mut self). When I try to get the root of TrustedPromise, it throws an error saying “cannot move out of borrowed content”. lines 122, 124, 136, and 138
the root() of TrustedPromise requires self parameter. In line 101, with let context = fetch_context.lock().unwrap(); which is type MutexGuard, which derefs to &T. When we try to access the Rc<Promise> via context.fetch_promise.root(), the compiler throws a borrow error.
That helped me learn that Fetch isn’t working . I started debugging (which means, me = stressed out) and learned a few things:
metadata that is used for process_response looks good. It’s Ok(_) and has the fields that look not incorrect.
After promise is taken from FetchContext through self.fetch_promise.take(), no other line is called… WEIRD. WHY. Well, luckily, I was working at the Mozilla Office, and three(!) people helped me debug. Special thanks to @sanxiyn, @fitzgen, and @jimblandy.
So, after using the debugger, this is what we learned:
Frame is older with higher frame number, i.e. frame #6 is called before frame #5.
frame #6 shows that to_jsval was called. This in turn calls JS_WrapValue in frame #5. This in turn calls JSCompartment::wrap in frame #4.
JSCompartment::wrap is a C++ code in SpiderMonkey, a JavaScript engine. JSCompartment::wrap has a parameter that is this=&0x0. 0x0 is a null pointer!!! We have a memory-unsafety here!!! Woohoo!
Body
Read the spec and some more about Unicode encodings in order to understand the UTF-8 decoder. Wrote a little code. Progress was slow due to being sick today.
Things we learned:
When you write . after an object, it automatically derefs! For example, if I do fetch_context.lock(), I’m derefing fetch_context then applying the lock() method.
assigning different types to the same binding name (via let statements) seems to be acceptable practice, at least in some contexts.
0x0 is the synonym to null pointer in C++! If your stack backtrace includes 0x0 that’s probably not something you wanted :)
When debugging Servo, you can use the --debug tag, i.e. ./mach run -d ~/src/fetch_example.html --debug. Servo uses lldb debugger by default.
You can set a breakpoint, for example, if you want the code to pause when it calls rust_panic function, you can write b rust_panic<ENTER>run.
While you’re at the breakpoint, (or maybe some other time too but I’m not too sure) you can type bt which will print all the backtrace! COOL.
Rc and Trusted has to maintain a 1:1 relationship, and therefore, Trusted should not have a &self parameter because that could break that 1:1 constraint. In Servo’s promise, Rc counts the references, and therefore TrustedPromise has to be connected to the one and only Rc<Promise>, because otherwise, the reference count will be incorrect.
Wrote process_response method. I think the remaining relevant FetchResponseListener methods are process_response_eof (invoked when fetching response is complete) and process_response_chunk (invoked when fetching response body). But process_response_eof requires response trailer support, which is not implemented, and process_response_chunk can probably wait until the response body is implemented.
Turns out when Josh said to create FetchContext later when it’s necessary, he meant literally creating it further down in the method (like physically located further down). Haha oops! I started working on creating FetchContext!
Body
Started implementing the Body functions without ReadableStream. The spec refers to streams a lot, but servo doesn’t implement ReadableStream, so I am trying to figure out how to write things correctly using Vec instead. Set up skeleton code for implementing [text](https://fetch.spec.whatwg.org/#dom-body-text) for dom::Request and dom::Response. Then dug into dom::Response's `text()`, which led to writing bits of `consume_body()`, `run_package_data_algorithm()`, and `utf8_decode()`.
Things we learned:
In order to use Promise::maybe_resolve_native() and the like, it needs a JS Context parameter. JS Context can be obtained through self.global().r().get_cx(). JSContext is a context in which JS can be invoked, and is required by APIs that interact with the JS engine (or it can use a JSRuntime argument). It’s confusing to me, but for now, I’ll just think of it as a connector to the JS world! (probably not 100% accurate).
vec.drain(..3); removes the first 3 elements of a vec.
Today we had a monthly meeting with everyone, and it was gooood . Special thanks to Scott for the pep talk! Also, we picked and ate figs from the fig tree by Jeena’s home as a break .
Promise in Fetch
Today was indeed a different day! I started working on implementing the FetchResponseListener. FetchResponseListener is invoked when (I think) the network level fetch gets some data back. For example, a method in FetchResponseListener is process_response, which will update the response object with the data it got back from fetching.
Josh suggested not worrying about the FetchContext, which will be the struct to hold promise and response together, until later. Creating the FetchContext will require a lot of wrappings.
The fetch listener (FetchContext) has to be Arc<Mutex<T>>. Inside FetchContext, there will be response_object with type Response and promise with type Rc<Promise>. Both response_object and promise will need to be wrapped with Trusted to be shared across threads safely. Trusted is a “safe wrapper around a raw pointer to a DOM object”, so response_object and promise can be Trusted<Response> and Trusted<Promise>.
I think response_object should be wrapped wtih DOMRefCell to allow inner mutability, but we shall see. If this is true, response_object will be DOMRefCell<Trusted<Response>>..? Josh said that since FetchResponseListener will be implemented on FetchContext, calling self.response_object.root() will obtain a Root<Response> value in the callbacks that can be manipulated like usual.
promise is Rc<T> so we will need a method that will pull out Rc<T> from Trusted<T>, like self.response_object.root() would.
Body
Wrote step 34 of Request constructor to extract Body contents. The extract body method still doesn’t use ReadableStream so I’m not sure if it will need to be rewritten.
Step 7.3 of Response
Things we learned:
The difference between Mutex types and regular-ol’-mutable-rust-variables. Both only allow mutation of their data one thing at a time, through either & mut or for mutex lock() and unlock(). What makes Mutex special? It is specifically designed for sharing across threads (often used in conjunction with Arc), whereas regular mutable borrow is not. So, only one thread can safely access the same data at one time. On the other hand, regular-ol’-& mut will not be allowed by the borrow checker if you try to use it across threads.
A whole lot about network-level fetch! Network level fetch is the communication with the core resource thread that invokes fetch algorithms, as described in the spec. There are a couple Servo parts that already use the network-level fetch: XMLHttpRequest and script.
Rc<T> is not thread-safe, but Trusted<T> is, like in Trusted<XMLHttpRequest>.
TODO:
Promise in Fetch
make FetchContext struct (on hold)
Impl FetchResponseListener for FetchContext (may require helper functions)
resolve/reject promise in fetch (figure out how to use maybe_reject_error, etc.)
Body
implement the rest of the body interface for dom::Response
I feel like I didn’t make much progress today. I’ve been looking at how XHR is implemented the whole day, and couldn’t understand it very much What I get is that there needs to be an object (probably FetchContext) that will hold the intermediate Response, and communicate with Promise to get the status of fetch. Hopefully tomorrow will be different!
Body
Started to write the extract-body function until I realized it’s already been written in XHR.
Moved onto more of the Body logic. Not sure how ReadableStream will be dealt with. I feel like a lot of what I’m doing will cross tracks with what Jeena’s doing. We’ll see…!
Things we learned:
We went to the monthly Rust meetup today. We learned about some patterns we should and shouldn’t do, a shout-out to clippy, and a C to Rust converter (wow!). We saw a lot of the Rust community in person (they flew in from around the world for the upcoming RustConf this weekend), so it was pretty exciting!
TODO:
Promise in Fetch
make FetchContext struct
Impl FetchResponseListener for FetchContext (may require helper functions)
resolve/reject promise in fetch
Body
Continue with Body logic until I can’t no more! (And then ask jdm :P)
Yesterday was Labor Day, so we celebrated it by not working! Woohoo! Malisa is traveling back today, so I (Jeena) worked alone today.
Things we did:
Promise in Fetch
jdm is back! He rebased his promises branch! The rust compiler still panics instead of throwing error as it uses the older rust version, but that’s ok! I can work around it.
It turns out there’s a lot more to do with implementing promise in fetch so I spent the day trying to understand what I need to do. Roughly, there are two things I can do:
figure out how to reject/resolve Promise in fetch. Promise::maybe_resolve_native is probably a better choice than Promise::maybe_resolve because they take regular DOM objects. This seems partially dependent on the next thing.
implement FetchResponseListener in fetch.rs. This turns out to have a lot more pre-requisite infrastructure! fetch.rs needs a FetchContext struct that will store the intermediate fetch. XMLHttpRequest is done very similarly to fetch, so I should look into how XHR is implemented in Servo. How XHR implements FetchResponseListener is here.
Promise doesn’t have to be rooted! Whaaaat. jdm says “Rc would usually be unsafe but Promise is designed in such a way that it's safe, whereas Rooted would be incorrect." Whaaaat? I don't even understand! We'll find out the reason later...
TODO:
Promise in Fetch
make FetchContext struct
Impl FetchResponseListener for FetchContext (may require helper functions)
Added Response test results, and broke down Body implementation related test failures.
Promise in Fetch
Here are my observations so that I can let jdm know when he’s back:
When Fetch.webidl and window.rs/workerglobalscope.rs state that fetch() returns a void, and fetch() does return a void, it compiles.
When Fetch.webidl and window.rs/workerglobalscope.rs state that fetch() returns a void, but fetch() returns Promise, it compiles. This is strange because the compiler should throw a type mismatch error.
When Fetch.webidl or window.rs/workerglobalscope.rs state that fetch() returns a Promise, and fetch()does return Promise, compiler fails with this error.
This rust bug is fixed with the latest nightly which Servo uses. When I rebase jdm:promises on top of the latest servo:master, a lot of conflicts happen and I’m not sure how to resolve them as I’m unfamiliar with the changes. I tried a few approaches (not really organized…) and they all have failed
Response
Waiting for merge/squash time!
Body
Started writing Body implementation for Response! Spent some time understanding why it’s a double Option: pub body: Option<Option<UnionTypes::BlobOrFormDataOrStringOrURLSearchParams >> (thanks Jeena! :D)
Things we learned:
Chrome and Firefox are both outdated with their Headers get and getAll functions!
TODO:
Promise in Fetch
I think what I can at this moment is done. I want to know how to solve the issue explained above.
We spent some time looking into how Firefox and Chrome implement Headers . Interestingly, they don’t return combined-values when you “get” or “get-all”, just an array of values.
Response
Refactored the code to get rid of the internally stored net_traits::Response. It compiles and passes tests.
Only thing I’m unsure about is the how to handle internal_response, now that there is no longer a net_traits::Response in dom::Response.
Fixed minor error: Status method should return net_traits::Response’s raw_status’s status, not net_traits::Response’s status.
Learned that it might be a good idea to refactor the code and remove the use of net_traits::Response altogether from dom::Response. There are pros and cons to this.
Categorized the tests! I haven’t filed the issues yet, but it boils down to roughly two large groups:
“Promise is not defined”: While the test messages are saying promise is not defined, these tests are in fact related to body. Body has a few methods that return Promise.
“xxxxdict is not iterable”: OpenEndedDictionary needs to be implemented. What Nick said about this: “OpenEndedDictionary isn’t supported in HeadersInit, bindings glue tries to convert the object into something that is supported in HeadersInit. The object is not a Headers object, so that doesn’t work. Then the glue code tries to treat it as a Sequence. However, it is not an iterable sequence, so it throws the error you’re seeing.”
There are a few notes:
Each API has a -idl.html test file that are currently timing out. I’m not exactly sure what they do, but it looks like once webidls are fully implemented, these tests will pass.
Some subtests related to stream like readableStreamfail. I’m not sure if stream is something we can implement or is already implemented. Will have to ask someone knows more about this.
Response is currently throwing an error about network error code. Malisa will be working on this!
Response
PR is finally ready to be merged (or so we thought), but Jeena discovered a test which is failing which should be passing, so I’m fixing that up.
Body
Tried to understand how/where I should be implementing Body. Decided to start with writing body’s extract method.
Things we learned:
In JavaScript there is a distinction between for ... of loops and for ... in loops. E.g.
In Python, for x in foo is the same as in JS, for (x of foo). In this case, x is the object you ultimately want to view or manipulate.
In Python, for x in foo.keys() is the same as in JS, for (x in foo). In this case, x is the key to the dictionary you might what to iterate over.
TODO:
Response
Figure out how to encode StatusCode 0 as an Enum, which is not supported currently.
Body
Start implementing extract as well as I can w/o ReadableStream
Published a blog post about computer memory, move, clone, and copy!
Promise in Fetch (Jeena)
I rebased Fetch implementation on top of jdm’s branch, and tried to use Promise in fetch(). Strangely, it’s causing the Rust compiler panics unexpectedly. I’m not sure how to move forward…
Test Curation (Jeena)
Haven’t started on this yet. As I’m lost about Promise in Fetch, I’ll work on this first.
Response
Still fixing things. Currently in git rebase hell.
Things we learned:
By doing let hello = b"hello";, an array is created. An array has a static length. So in our Headers code, we ended up making unnecessary transformations here. We wrote combined_value.push(b","[0]); which means, “create an array that has length of 1, and whose only element is a comma byte. Then, take the first element of it and add that to combined_value. We can improve this line by writing combined_value.push(b',');
Finally submitted PR. Fixed up the code based on feedback I got back.
Fetch
I wrote the algorithm to send the fetch message to the resource thread (net_traits).
It looks like the parts I can do right now are mostly done, but it needs double checking!
Things we learned:
Stefan showed us some examples of asynchronous code written in AngularJS and also CoffeeScript, as an introduction to Promises.
Closures! We went to Portland’s Papers We Love meetup yesterday and learned about Garbage Collectors. It seems like with JS closures, sometimes you might have to move stack-created objects to the heap. Interesting!
TODO:
Promise in Fetch
implement the Promise return value for fetch() on top of jdm’s branch
Test Curation
curate the failing tests and opening an issue for each category so that others can pick up where we left if we don’t finish implementing fetch, i.e. tests that fail because of Promise, because of OpenDictionary, etc.
Body (Malisa)
Start implementing Body for Request and Response
Miscellaneous
Publish a blog post about move, clone, and copy! (Jeena)
Set up blog and write about deref coercion, etc (Malisa)
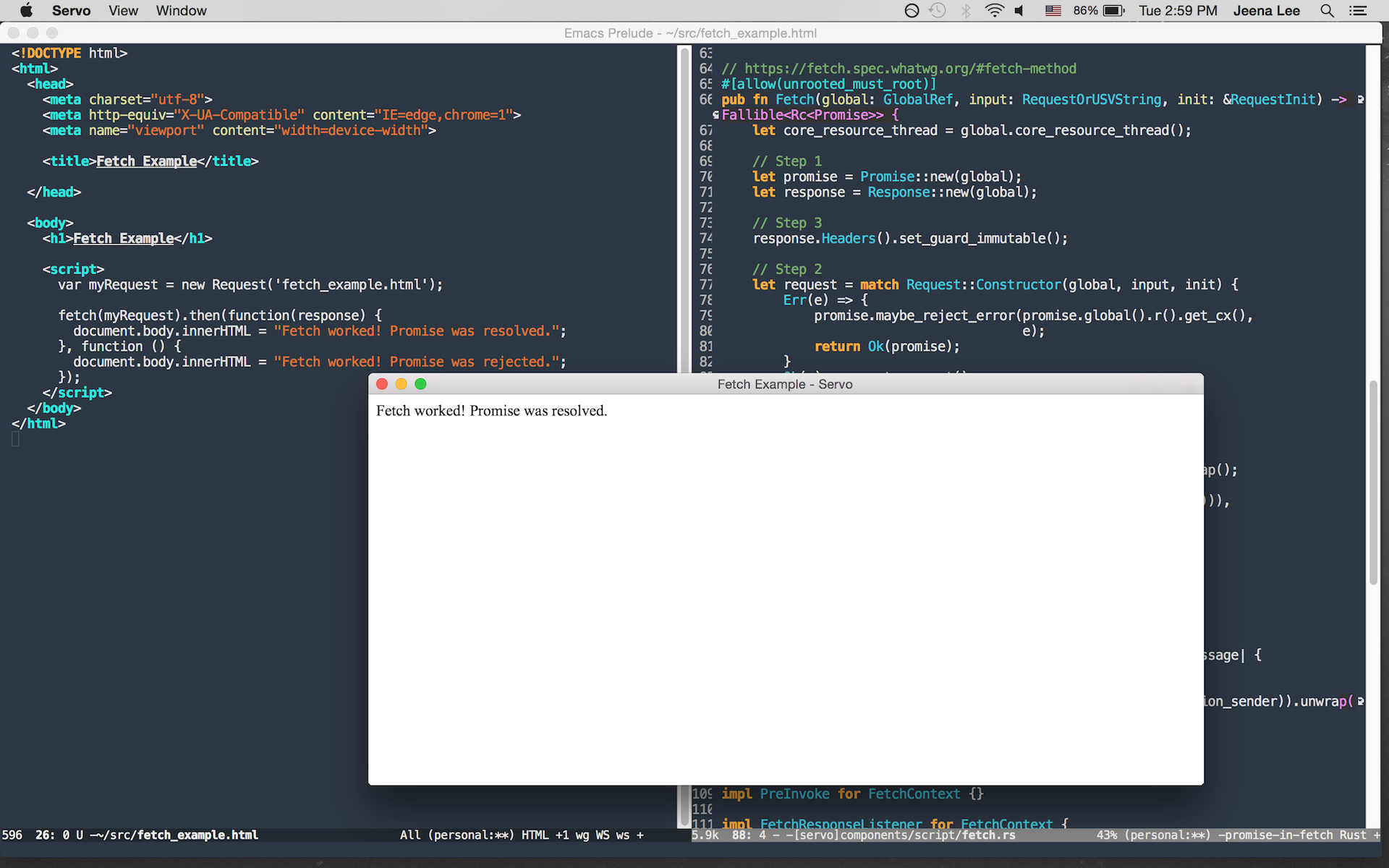
Set up the skeletons for Fetch. It was a tricky process. Fetch is defined in WindowOrWorkerGlobalScope.webidl which is a newer addition to the spec and was not present in Servo. I had to add it to Servo, and WindowOrWorkerGlobalScope is not a interface object, so no bindings were created. The compiler told me that dom/window.rs and dom/workerglobalscope.rs had to implement Fetch(). So what we decided to do is have a script/fetch.rs where the Fetch method will live, and have dom/window.rs and dom/workerglobalscope.rs delegate the Fetch method to script/fetch.rs.
Response
Ended up having to replace instances of RawStatus (which takes a utf-8 encoded Cow-str) in Servo’s codebase with (u16, Vec<u8>), which is not UTF-8-dependent. I spent the whole day re-building and finding new places in the codebase which were affected by this change, fixing, and re-building again! Finally the relevant test is passing though :)
Things we learned:
Don’t spend too much time trying to predict the repercussions of a change in your Rust code. (I do this a lot - Malisa) Often-times the Rust compiler will tell you what those repercussions are, and save you a lot of time, even though you might get surprised by some unexpected errors while building your project!
TODO:
Fetch
It seems like a huge chunk of Fetch is already implemented in net/fetch/method.rs. Figure out how to wrap script/fetch.rs around net/fetch.
Response
update tests, clean up code, and submit the PR already!
Miscellaneous
Publish a blog post about move, clone, and copy! (Jeena)
Before Josh goes on a vacation, ask him what we should work on next week.
PR sparked some discussion… This might take a bit longer to resolve. Tried to implement header values to be stored as Vec<Vec<u8>> in which the inner vector is one header value. Not sure how this will mesh with hyper::header::Header existing methods. (Or, how do I separate the different header values? Will the comma have to be added as a separate vector?)
Fetch
Started working on this, and encountered some ~issues~ challenges! See TODO.
Response
Still dealing with wpt test errors. Fixed one (adding dummy argument to constructor so it takesthe right number of arguments), still dealing with a UTF-8 conversion error on one of the tests.
Things we learned:
if you want to import the latest changes in a file from a different branch to your current branch:
git checkout remote-name/branch /path/to/file
TODO:
Fetch
It looks like fetch requires WindowOrWorkerGlobalScope which is not implemented yet. Hear what Josh has to say, and do that!
Response
Submit the PR once tests pass.
Start trying to understand the work that would go into implementing the body APIs, working on top of jdm’s Promise branch (Malisa)
Submitted a PR about implementing iterable for headers.
Submitted a PR for updating DOM Headers. Making more tests pass is fun!!!
Response
Finished up implementing dom::Response. Now dealing with wpt test errors.
Things we learned:
Fetch requests originate in the script thread via a JavaScript function. The request gets sent to the dom objects (e.g. dom::Request) and are sent to the resource thread using net_traits::CoreResourceMsg. The resource thread calls the actual HttpRequest. The response is sent back to the script thread and the original Promise is resolved. Yay! This is just a broad overview…
TODO:
Fetch Method (Jeena)
Read about fetch. Decided to start working on fetch (one of jdm’s suggestions). He wrote:
“Start working on the actual fetch() API, focusing on the code that deals with the arguments and initiating the request and ignoring the return value for now.” At this moment, I won’t have to worry about Promise because “there’s enough work that goes into dealing with the arguments to the function and initiating the request that the promise-related bits can be done separately and subsequently.”
We both enjoyed our long weekends. It featured swimming, the Seattle Opera, a movie triathlon, air conditioning, and Thai food. We feel energized for the second half of RGSoC!
Things we did:
Headers (Jeena)
After addressing a couple comments, the PR for including “content-type” was approved.
It turns out headers list should be sorted before iterating over. Currently figuring out how to sort a hash map. Probably make a vector of the hash map elements and sort the vector.
Response (Malisa)
Implemented more dom::Response methods: Type, Url, Redirected, Status, Ok, and StatusText.
Things we learned:
Was able to use destructuring with ref and & in a match statement, which helped me understand those concepts a little more. (Malisa)
BTreeMap is a hash map in which the elements can be sorted! (Jeena)
TODO:
Headers (Jeena)
Figure out how to sort a hash map/iterate through a hash map and create a sorted vector.
Wrote a rough version of iterable implementaton. Additional tests pass.
Started implementing parse for content-type header name
Response API
Got completely confused about what I’m supposed to do next. Gave up trying to reconcile the spec, the multiple hyper::header::Headers objects, and the nuances of implementing for Servo (for now).
Focusing on just writing the Response API as though I only have one version of hyper::header::Headers in dom::Headers…
Things we learned:
Threads vs processes (thanks wiki!): In the operating system, two “processes” do not share memory. A process can contain multiple “threads” which share memory and other resources.
This is rather relevant to the whole multiple-references-to-the-same-object problem. You need to be aware of whether the references exist in different processes (if so, you can’t use the Rc or Arc types, which are for sharing within a process).
TODO:
Response API:
Work on the constructor while figuring out what to do next
My friend Malisa and I have
been hacking on Servo this summer. We started from scratch, with no
experience writing Rust, let alone compiled langauges. It's
been challenging and fun! One of the trickier Rust concepts to
understand for me was Rust's references and
borrowing.
Ownership in Rust is in many ways like owning a coloring book. You can
have all your friends come look at it together and flip through the
pages. However, they can't color in it. This is an immutable borrow in
Rust lingo.
But say you actually want to create a collective art piece with the
coloring book. You can lend it to one friend at a time and tell them
they can color however they want, or mutably borrow in Rust
lingo. They have to give the book back to you when they're done, and
you may lend it to the next friend, and so on0. If you tried to let
two friends color at the same time, they can end up fighting to color
the same spot.
These are the two rules of Rust's borrow system:
If it's mutably borrowed, it must be the only borrow that currently exists.
Otherwise, many friends can borrow immutably at the same time.
In both cases, if the lender wants to color the book, then they
must get it back from the borrowers first. How else would you color a
book you don't have in your hands?!
I've found that making the compilation fail, and then reading the
compiler's detailed messages is a great way to learn these new
concepts. Steve Klabnik,
the author of "The Book", wrote an
awesome introduction
to Rust's borrow system, so let's mess
with one
of its examples, break things, and learn!
Let's start with something simple that compiles:
fnmain(){letmutx=5;letmuty=x;y+=1;println!("x is: {}",x);println!("y is: {}",y);}
warning: variable does not need to be mutable, #[warn(unused_mut)] on by default
--> <anon>:2:9
2 |> let mut x = 5;
|> ^^^^^
x is: 5
y is: 6
The compiler helpfully warns that x didn't have to be
mutable. But why? It's because y ends up being a separate
copy of 5, and x is never modified in the
code. You can tell that x and y are two
different things in the memory, because the printed values are
different.
What if we didn't want to copy x into y,
and wanted changes to y to apply to x?
fnmain(){letmutx=5;letmuty=&x;*y+=1;println!("y is: {}",y);}
error: cannot assign to immutable borrowed content `*y`
--> <anon>:5:5
5 |> *y += 1;
|> ^^^^^^^
error: aborting due to previous error
What happened? This time, y is not a copy
of x. Instead, y is a reference
to x, and therefore, it had to be dereferenced
before 1 is added to y. One important thing to note is
that y is an immutable reference, even
though y itself is mutable! That is why the compilation
fails. y didn't have the permission to change the value,
yet it tried to do so anyways.
Now that we know what's going on, let's fix this code and make
the compiler happy again!
fnmain(){letmutx=5;letmuty=&mutx;*y+=1;println!("y is: {}",y);}
error: cannot borrow `x` as immutable because it is also borrowed as mutable [--explain E0502]
--> <anon>:7:26
3 |> let mut y = &mut x;
|> - mutable borrow occurs here
...
7 |> println!("x is: {}", x);
|> ^ immutable borrow occurs here
8 |> }
|> - mutable borrow ends here
<std macros>:2:27: 2:58: note: in this expansion of format_args!
<std macros>:3:1: 3:54: note: in this expansion of print! (defined in <std macros>)
<anon>:7:5: 7:29: note: in this expansion of println! (defined in <std macros>)
error: aborting due to previous error
Compilation
fails! The compiler gives a pretty good explanation. It says that
println! cannot immutably borrow x
because x is already mutably borrowed
by y. This violates the first rule of Rust's borrow
system: when something is mutably borrowed, there cannot be other
borrows.
The Book
shows a
way to correct this code by using curly brackets to introduce a
nested scope.
fnmain(){letmutx=5;{lety=&mutx;*y+=1;}println!("x is: {}",x);}
error: unresolved name `y`. Did you mean `x`? [--explain E0425]
--> <anon>:7:26
7 |> println!("y is: {}", y);
|> ^
<std macros>:2:27: 2:58: note: in this expansion of format_args!
<std macros>:3:1: 3:54: note: in this expansion of print! (defined in <std macros>)
<anon>:7:5: 7:29: note: in this expansion of println! (defined in <std macros>)
error: aborting due to previous error
The compiler lets us know that y does not exist. This is
because y is defined inside the inner scope delineated by the pair of curly brackets, and outside
of them, y doesn't exist! Introducing inner scopes gets very handy
when you want to define things only temporarily.
The Rust compiler does a great job of pointing out possible sources of
error in the code. Compilation errors are not scary, and they're in
fact a great conversation starter with the compiler. Try introducing
different kinds of errors, and see how the compiler responds. From
these conversations, I find myself learning new concepts that I didn't
know before, and writing better code over time.
Now you should go break some code! Thanks for reading!
0 Or maybe you'll give the book to your friend forever, in which case
you're giving away your ownership, but we won't cover that concept in
this blog post.
Submitted PR to wrap hyper::header::Headers in Rc. This solution may or may not work for the Response API, however, because Rc doesn’t work across threads. Instead of manipulating the same object in multiple places, I might end up having to just work with one version of hyper::header::Headers, or replace Rc with Arc.
Wrapped net_traits::response::Response’s headers (hyper::headers) with Rc and RefCell.
Fought with the borrow checker the whole day. Implemented clone for net_traits::response::Response and dealt with side-effects of using internal Rc types… x_X
Request API
Decided not to file a spec issue, but clarified the reasoning for the additional step in request.rs in the comments.
Made the code more readable, and removed unnecessary parts.
jdm gave me the permission to squash! Woohoo! Merge is near.
Things we learned:
Parentheses are useful! Long story short, wrapping parentheses around (*gadget1.owner) applies the deref * to just gadget1.owner, which is just what I needed. :)
Reflog is what git uses to keep track of updates to the tip of branches, including those that are invisible on git log! This acts as a great safety net. For example, if you want to undo git rebase, you can find the HEAD of pre-rebase, and git reset --hard to that HEAD.
You cannot modify a field that is in a borrowed context. This is a sample code.
The reason there are r and referrer is that if it’s written into one line (let r_referrer = self.request.borrow().referer.borrow()), it will throw a life time error. See here.
In match if referrer does not have &*, it will throw a type mismatch error. This is because referrer is a Ref<> type, and it is trying to match against Referer enum.
So, you may want to dereference (*referrer) so that you can use referrer as a Referer enum type through deref coercions. However, that will be trying to move referrer out of borrowed context.
And therefore, you make it explicit that referrer is borrowed object, while dereferencing it: &*referrer
Similarly, in the last match arm, u_c is created because u is a ref. If you were to write u.into_string(), you will be trying to move u out of borrowed context.
TODO:
Response API:
Deal with current build errors (now the side-effects of wrapping headers with Rc and RefCell are appearing in places like fetch/methods.rs, uh oh)
And then modify net_traits::request::Request and dom::headers as well……
Implement JSTraceable for RefCell in dom::Headers
And then finally work on dom::Response!
Request API:
If merge happens, start working on making Headers iterable based on jdm’s PR.
General:
Finish up writing blog post, intro to Rust’s ownership.
Small PR for default bytestring values in dictionaries got merged
Spent most of the day trying to figure out how to best make references between objects within the Response struct.
Request API
Turns out I had to debug the out of Request, not Headers!
Fixed a bug. More in depth description below.
More tests are passing! I updated the expected test results.
Things we learned:
How to use reference-counted boxes: Rc<>. They are a way to refer to the same internal object in multiple places. Different from RefCell, which I believe is more of a way to provide mutability of already-borrowed objects.
When debugging a Rust code, you can print the memory address of the object through:
letx=5;println!("{:p}",&x);
Approach debugging as if performing a scientific experiment. Do you have a hypothesis where it might be breaking? Sprinkle some print statements in the code, or set breaking points in the debugger. Study the results. Can you find a pointer that would lead to the next hypothesis? Repeat! And don’t get frustrated!
A Fun Debugging Tale
Below is the test that was failing, and I was debugging:
test(function(){varinitialHeaders=newHeaders([["Content-Type","potato"]]);varinitialRequest=newRequest("",{"headers":initialHeaders});varrequest=newRequest(initialRequest);assert_equals(request.headers.get("Content-Type"),"potato");},"Request should get its content-type from the init request");
The test creates an initialRequest with initialHeaders, and creates a request with the initialRequest. Then tries to assert that request has the same Headers as the initialHeaders. For some reason, request’s Headers becomes an empty object, so I was trying to figure out why.
Here is the spec for constructing a Request object. request’s Headers is emptied at Step 29. It gets filled with headers_copy at Step 31. It turns out headers_copy was empty, and therefore at Step 29, the request’s Headers was getting filled with an empty Headers object.
headers_copy is set at Step 28. It states “If init’s headers member is present, set headers to init’s headers member.” It turns out that init’s headers didn’t exist when request was constructed. But it did exist when initialRequest was constructed.
So I had a hunch that maybe it was mixing up init and input. Constructor takes input: RequestInfo and init: &RequestInit. I printed out input.headers, and it was the same as initialHeaders. Once I added another logic in Step 28 to match input to Request and set headers_copy to input.headers, the test passed! I guess it was the cause for a few other tests to fail, so more tests are passing now.
TODO:
Response API:
Update net_traits::Response and net_traits::Request and dom::headers::Headers to wrap Rc<> around their internal hyper::header::Headers objects. That way they will be clonable into reference-counted boxes.
After that hopefully I can actually do work on the Response constructor….fingers crossed…
Request API:
Figure out whether I should file a Fetch spec bug.
General:
Finish up writing blog post, intro to Rust’s ownership.
Had our monthly meeting with everyone! Everyone is doing well. :D
Blast from the past! Back to Headers API.
With the help of Stefan and the rust playground, we realized there were bugs in the is_field_content and Append functions in the Headers API. After fixing these, more of the Headers API tests passed! Oops…
Response API/CodegenRust
Received feedback on bindings generator PR. Once merged in, these changes will allow me to move forward with Response WebIDL implementation.
Drew a flowchart/diagram to understand each step of the response API.
Request API
Realized that the reason Request tests fail is (at least partially) related to Headers not properly working.
Currently it looks like the Headers object is not properly created, or Headers::Get does not get the correct value.
Had bubble tea
Things we learned:
--log-mach /path/to/log/output can be added when running servo tests to see verbose output and println’s, for help in debugging
Remember to build after making changes and before running tests!!! ;)
TODO:
Response:
Continue with Response constructor. Maybe, just maybe, be done with the constructor by Friday?
Figure out how to connect the two headers_list instances in the Response constructor using Rc.
Request:
Debug the out of Headers.
General:
Finish up writing blog post, intro to Rust’s ownership.
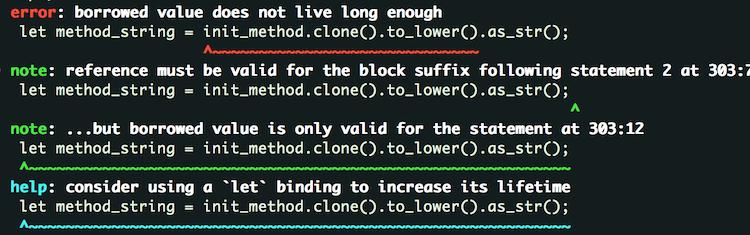
If you try to compile it, you may get an error that looks like:
The reason is that to_lower() gives back a String, and as_str() tries to give a reference to that String created by to_lower(). However, that String would not exist anymore because it was consumed by as_str() and therefore, the compiler throws an error saying that the borrowed value doesn’t live long enough.
To fix this issue, the compiler suggests using let binding to increase its life time. In other words, the one line code can be expanded as following:
Again, it would try to borrow integrity_metadata from self.request which would be transformed to Ref<'_, net_traits::request::Request> after self.request.borrow(). This error can be resolved by expanding the code above to this:
ASCII is limited to only 128 characters, via a 7-bit character set (so, fits in one byte). UTF-8 is flexible, on the other hand, and can represent characters that require between 1 and 4 bytes. The first 128 characters are the same for ASCII and UTF-8. UTF standards encode the “code points” as defined in Unicode.
This is useful for us to know because we are often converting between ByteString types, which are basically sequences of 8-bit unsigned integers, and characters or Strings. Many of the specs we have to follow reference these encodings. Knowing hexadecimal representation of characters is also useful.
Met with Stefan who showed us some useful tools for looking at Requests/Responses/Headers and also cleared up some questions which had been bugging us.
Things we learned:
dom::bindings::js::MutNullableHeap allows lazy construction of objects (they can be initialized only when you need them)
The cache-control header “directives control who can cache the response, under which conditions, and for how long”.
Also learned about cookies from Stefan. Plus neato command-line tools like zsh-autosuggestions and zsh-syntax-highlighting. Also Charles for web debugging.
We asked Stefan about where to find the actual code that makes the HttpRequest to the remote server. The ultimate goal of all this code we’re writing is to make an HttpRequest (well, one of the goals), yet the code we’re writing seems to dance around that very topic while never actually making the call to the remote server. So this helped clarify things a bit!
Continued working on Constructor. Currently, up to step 15 is compiling successfully. A draft up to step 24 is written.
Things we learned:
There are different types of references in Rust. one of them is &, but you can also have “user-defined custom smart pointers” or wrappers with particular behavior for references, like Ref and RefCell. A helpful explanation is here and here.
You can customize the type name in a use statement. For example, instead of writing use hyper and writing hyper::header::Headers throughout the code, you can use use hyper::header::Headers as HyperHeaders and use HyperHeaders in the code body.
Air conditioning is wonderful!
TODO:
Response:
If Headers is accepted, start working on Response.
Wrote a couple helper methods for finding associated and current url, given a url list.
Started writing constructor step 13.
Headers API
Finished up the remaining functions defined in the webidl. My job was made easier because I don’t need to implement iterable<ByteString, ByteString> just quite yet.
Things we learned:
Even though the result of the two code blocks below are the same in practice, it’s only due to the rust optimizer.
This first version only ever deals with one memory location on the stack
This second version instructs Rust to create two memory locations for each valid_name. Only due to the Rust optimizer does the computer realize that it can reuse the same spot.
When returning a reference to a RefCell, wrap the content with Ref which can be done through Ref::map.
fnget_associated_url(req:&net_traits::request::Request)->Option<Ref<url::Url>>{// if into_inner() is used, req is no longer accessibleleturl_list=req.url_list.borrow();ifurl_list.len()>0{// .first() returns an Option, and therefor needs unwrap()Some(Ref::map(url_list,|urls|urls.first().unwrap()))}else{None}}
TODO:
Headers:
Submit PR after final tests and squashing commits
Response:
If Headers is accepted, start working on Response.
Realized that the hyper::header::Headersset_raw() and get_raw() act as though there is only one entry for a given unique header name.
Spent much of the day understanding the consequences of this (do we re-write our Headers append() method or re-write hyper::header::Headers?), piecing together instructions from various specs, and planning the next steps –> Decided to go with the current hyper::header::Headers implementation.
Currently re-working the append() method and other Header API functions.
Things we learned:
if let is handy if you want to match for only certain cases. For example, following code snippets are the same.
ifletRequestOrUSVString::Request(req)=input{// Do stuff}matchinput{RequestOrUSVString::Request(req)=>// Do stuff,RequestOrUSVString::USVString(_)=>{},};
Turns out there is a Request struct already written in Servo. But the names it uses are different from what the codegen generates from the webidl. So I have to write Into implementation to allow translation between the two.
Completed writing Into implementation.
Headers API
Worked on filling in the constructor for the Headers API, following the spec.
Things we learned:
Into allows Rust to “translate” between two different objects.
We learned about the very basics of trace garbage collection.
Trace Garbage Collection
In a garbage collected language (such as JavaScript and Python, but not Rust), GC manages the memory by freeing it when the memory occupant is no longer in use. Whenever a new object is created, it is done so through GC and GC will add to its set of objects created.
Once in a while, GC will be triggered, probably through the danger of memory running out. GC is expensive, and therefore, it should not be triggered too often. When GC is triggered, it traces memory, checking which objects are referenced, in other words, still in use. Tri-color marking is the one we learned about, and its wikipedia page provides an excellent summary.
Long story short, GC has the ability to compare the sets of objects created and objects that are still used. GC will free the memory occupied by whatever is in the difference.
Figured out how to include Body in the Request API. For now, because we are using only a single Body attribute, it’s better to implement that attribute in the Request struct.
There are Request object and request, and they are different! Request object is exposed to JS. request that is part of Request object is used internally.
Headers API
Malisa worked on fixing an issue that has been blocking her work.
After some final changes, the Append method is finally merged in.
We found out that our scholarship applications for attending RustConf were accepted. We’re both really excited to go in September, meet everyone we’ve met through the Servo community, and learn a lot.
Continued working on the Request API.
Made Body.webidl so that Request can implement Body
implemented all readonly attributes, except headers
Started working on Constructor
The Headers append method is merged, but all the other Headers methods still need to be implemented.
Started working on the Headers constructor. Discovered a bug in the generated UnionTypes.rs file, which we will fix.
Chatted with our mentor Scott and updated him on our progress, challenges, and goals for the next week.
Things we learned:
git stash is useful for switching branches on the fly
Addressed the feedback that we missed yesterday, and new feedback we received today.
We got an approval from Josh! Woohoo!
Started working on our next goals. Malisa will continue working on headers, and Jeena will start working on request.
Things we learned:
git rebase -i <remote>/<branch> allows you to squash the commits between the current HEAD and the HEAD of <remote>/<branch>. If you are on local features branch and know that local master is untouched, you can git rebase -i master.
Submitted PR#2 for code review, the append method for the Headers API. The code compiles on our machines locally but seems to fail Travis CI on github. Our coach @jdm also gave us a lot of good feedback which we are working through.
Spent the afternoon brushing up on Rust!
Things we learned:
Debugging: Rust is a compiled language, so code needs to be built before running it. This means that you can get errors at two different stages, compile-time and runtime. As opposed to an interpreted language like Python where errors are found as each line of code is executed in order (top-to-bottom), Rust code is parsed in its entirety during compilation and different types of errors are found in stages. Python debugging is like a straight celery stick, and Rust debugging is more like an onion, with layers. One side-effect of this is that when we build Servo, the errors do not appear in a “linear” fashion, and fixing one bug at line 20 does not mean that lines 1-19 are perfect.
Reflectors! For the past two weeks we have been mystified by the presence of Reflectors in Servo DOM objects. Today we learned that Reflectors are JS objects allocated by SpiderMonkey (Mozilla’s JS engine), that “reflect” the containing Rust object. An example of its use is here. This concept is hard to digest at first because it is circular: the JS reflector is embedded within the Rust DOM object, yet has a reference to the DOM object.
TODO:
Address all the feedback from PR#2, including a lot of refactoring and adding a new_inherited method (somewhat related to Reflectors).
Should we write tests for our append method and associated helper functions?
Come to a conclusion regarding the field-content production, i.e. here.
Started writing Append, i.e. putting every helper function together. Wrote if/then logic for going through Append method.
Ran into a lot of incompatible type issues. And we are still learning! :) :) :)
We decided to be more aware of each other when pair programming. :D
Used DOMRefCell instead of RefCell because DOMRefCell implements JSTraceable. With RefCell, the compiler threw an error saying it requires JSTraceable implementation.
The reason we need RefCell is that it allows interior mutability to immutable borrowed content. The header_list needs to be mutated while auto-generated HeadersBindings.rs will borrow Headers immutably.
Things we learned:
return can only return from the current function, i.e. you can’t return from an enclosing function in a closure.
match doesn’t introduce a new function or closure, so it is fine to return from a match arm
matchx{Ok(value)=>y=x,Err(e)=>returnErr(e),}
try! is awesome. Below two snippets would do the same thing.
Function to remove HTTP whitespace was already written in Servo! Though we don’t know if ByteString will be a valid input type, so we’ll just keep this knowledge in the back of our mind.
TODO:
Implement new() for our Headers struct.
Finish up writing Append.
Probably should use set.
As set requires the header name (which is a ByteString) to implement Into<Cow<'static, str>>, we might have to implement it ourselves (impl Into<Cow<'static, str>> for ByteString).
Re-organized a lot of our validate function we wrote yesterday.
We had misinterpreted the HeadersAPI spec. We were thinking way too far ahead.
But, the code we wrote yesterday will be useful in the near future, so .
We understood better what we need to do for validating Header name and value.
We will have to write parsers to do so.
Started writing different components for the parsers.
We added guard to our Headers struct.
We created enum Guard for guard.
We got a lot of practice using Result<>.
We filed an [issue] (https://github.com/whatwg/fetch/issues/332) at whatwg/fetch.
Things we learned:
How to add crate dependencies (assuming script is the root directory of our files):
In components/script/lib.rs, add extern crate unicase;.
In components/script/Cargo.toml, add use unicase="1.4.0".
Cow automatically handles copy and writing when you have a borrowed immutable reference.
Emacs tip “defining macro”:
C-x ( (define macro) C-x )C-e (execute macro)
String is guaranteed to be UTF8 and is heap-allocated (and therefore growable). &str is a string-slice. dom::bindings::str::ByteString is not guaranteed to be UTF8.
If Result only returns an error, use Result<(), Error>.
For Boolean matching in Rust, use &&.
Because the Headers API interacts with JS, JS garbage collector must be able to trace Headers API’s elements. In order to allow that, above a struct or enum that declares, add #[derive(JSTraceable, HeapSizeOf)].
Crate regex supports pattern matching on bytes. Add use regex::bytes to the code.
TODO:
Finish writing field name and field content parsers.
Figure out how to wrap our Headers struct around hyper::headers::Headers. Ask jdm!
Yesterday we attended the PDX Rust meet-up and saw Andy Grover give a presentation on his project Froyo.
Today we worked at the Portland Mozilla office to program on a really easy Servo issue just to get used to the workflow. With the help of our coach Nick we were able to submit our first pull request, which was accepted. :)
Things we did:
Re-factored some code related to Interval Profiling, specifically the calculation of the mean, median, minimum, and maximum of the time spent on various events. (Not related to the Fetch API, which is our main project.) The PR: here.
Upgraded Emacs configuration, e.g. rust-mode, and learned some best practices for using Emacs
Implemented step one of Headers.append() for the Fetch API (normalize), together with Nick.
Had a kick-off call to say hi, discuss various logistics, and the best way to ramp up to speed on Servo
We are planning on spending Thursday working on an E-Easy tagged Servo issue with our coaches, just to get used to the workflow
In terms of dividing our time between learning Rust and working on Servo, the consensus was that it is good to know enough Rust to understand basic Servo code, but it is also important to dive into the issues!
Decided to do work on our own Servo forks as opposed to a team fork. Learned how to reset our working repo to a particular fork, branch, or commit.
Ran into more build issues. Oddly, the build that worked for us yesterday didn’t work for us this morning. After some troubleshooting we got it to run again. In the process we learned:
Learned that we need to add #[dom_struct] before our headers.rsstruct declaration, and the first field of the struct has to either be a Reflector or the object it inherits
To-Do:
Go to the Rust PDX meet-up tonight!
Learn more Rust
Ask Josh how often to pull from Servo (pulling and re-building every day might result in a significant amount of our time spent dealing with build failures)
We had a nice long Independence Day weekend and are happy to be back coding on Servo!
Things we did:
Added skeleton code for the Headers API (part of the Fetch API)
Ran into PR issue #12271 while building the code on both Ubuntu 14.04 and OSX, indicating that the bug was a more general issue than it was originally thought to be
Learned that rebuilding Servo after making code changes sometimes requires running the ./mach clean command in order to clear the “build cache” prior to running ./mach build --dev. Also ./mach bootstrap-rust --force
Applied for RustConf scholarships
Looked into optimal git workflow for Servo and RGSoC
To-Do:
Learn more Rust
Finish implementing the Headers API skeleton, as well as the Request and Response API skeletons
Tomorrow, our summer begins. We will hack on Servo, a web browser engine built with Rust. Our goal of the summer is to implement the JS Fetch API in Servo. We are blessed to have support from our wonderful coaches (Morgan, Nick, and Stefan), mentor (Josh), supervisor (Scott), and of course Rails Girls Summer of Code! Many many thanks to everyone.
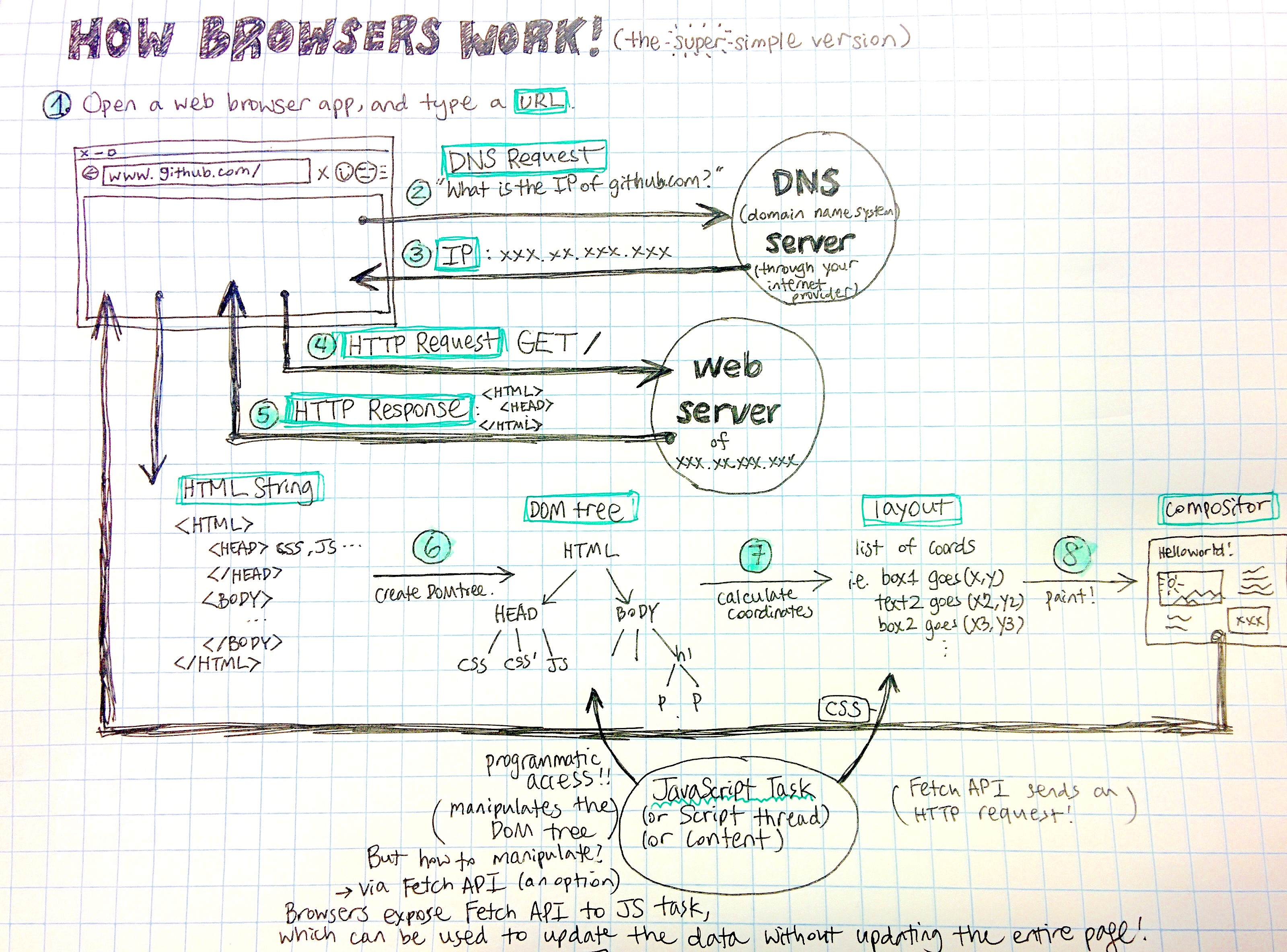
Tonight, we learned about the big picture of the Fetch API.


{kind=link}
{kind=link}
{kind=link}
{kind=link}